David J. Birnbaum (University of Pittsburgh)
Department of Slavic Languages and Literatures
1417 Cathedral of Learning
Pittsburgh, PA 15260 USA
djbpitt@gmail.com
Erin Alpert (University of Pittsburgh), Hillary Brevig (University of Pittsburgh), Drew Chapman (University of Pittsburgh), Alyssa DeBlasio (University of Pittsburgh), Julie Draskoczy (University of Pittsburgh), Yelena Forrester (University of Pittsburgh), Olga Klimova (University of Pittsburgh), Michelle Kuhn (University of Pittsburgh), Raffaele Ruggiero (Pittsburgh, PA), Oscar Swan (University of Pittsburgh), Elise Thorsen (University of Pittsburgh)
Copyright © 2008 by the authors. All rights reserved. Last revised 2015-10-17.
Abstract: The present report describes the construction of a technologically innovative electronic edition of the Old Church Slavonic “Life of St. Paul the Simple” from the Codex Suprasliensis.
1. Note
2. Introduction
3. The Project
4.1. Description
4.2. What's interesting or innovative about the Main view
5.1. Description
5.2. What's interesting or innovative about the Page view
6. The Linguistic search interface
6.1. Description
6.2. What's interesting or innovative about the Linguistic search interface
7. The Full text search interface
7.1. Description
7.2. What's interesting or innovative about the Full text search interface
8. The use of XML and related technologies
9. The Character set and fonts
9.1. Description
9.2. What's interesting or innovative about the use of character sets and fonts
10. Conclusions
Appendix A. About the Codex Suprasliensis
Appendix B. Software
This report describes a pilot project that has been archived, and is no longer maintained on line. The technology is in the process of being adapted into the Codex Supraliensis project at http://suprasliensis.obdurodon.org. (Note added 2015-10-17)
St. Paul the Simple lived in the early fourth century AD, and was a contemporary of St. Anthony the Great, a founder of Egyptian monasticism. The story of his life is found in Palladius of Helenopolis’s Lausiac History, an account of the lives of Egyptian hermits. The oldest extant Slavic copy is found in the Old Church Slavonic (OCS) Codex Suprasliensis, an undated (ca. eleventh-century) menaeum for the month of March. Several properties of the “Life of St. Paul the Simple” (very early Slavic text, non-biblical text, extant Greek original, text not otherwise represented in the OCS canon) make it an important object of study for Slavists, and also provide an opportunity to explore the possibilities afforded by modern electronic text technology to produce an edition that would support research and teaching as effectively as possible. In addition to its immediate utility for research and pedagogy, we envision this rather small-scale project (the text occupies 157 lines in the manuscript) as an opportunity for technological innovation that can then be applied to the development of similar editions of larger texts in the future.
In spring 2008 the authors of this article prepared exhaustive linguistic annotations for each of the approximately 800 words in the text of the “Life of St. Paul the Simple” as part of a training exercise in an introductory graduate course on Old Church Slavonic.1 As we completed these annotations, which had been intended initially merely as a pedagogical training activity, we recognized that they could serve as the basis for a technologically innovative electronic edition, for which we established the goals of identifying and satisfying as many research and teaching needs and applications for this text as possible. In particular, we wanted to ensure that scholars and students would be able to read the text in OCS, Greek, and English both separately and in parallel; to identify the linguistic properties of every word in the text; to conduct searches according to those linguistic properties; to conduct string searches; and to examine facsimile reproductions of the manuscript pages alongside character-based transcriptions.
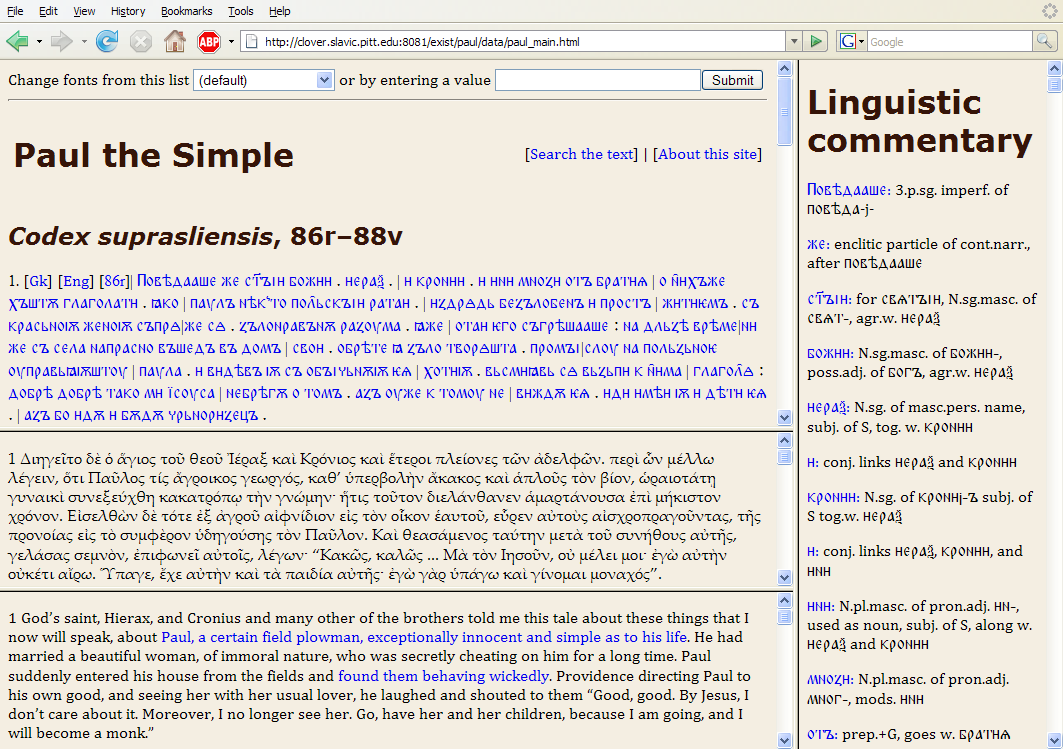
Figure 1. Main view.
The Main view (Figure 1) is a framed interface with four windows, three on the left and one on the right, with the following characteristics:
In addition to the principal text in these four windows, the OCS window contains three additional features. One is a link to an About this site page, which describes the genesis and implementation of the project, identifies the authors, and provides a brief description of the “Life of St. Paul the Simple” along with a list of abbreviations used in the linguistic commentary. Another is a link to a Search interface, described below. Finally, there is a font-switcher at the top of the window, which lets the user select on the fly the font that will be used to render the OCS text.
In 2004 one of the authors of this paper developed a simpler version of the Main view interface as part of a project for publishing annotated editions of Russian fairy tales, which we called “The Annotated Afanas′ev Library” (“AA”) (see Figure 2).
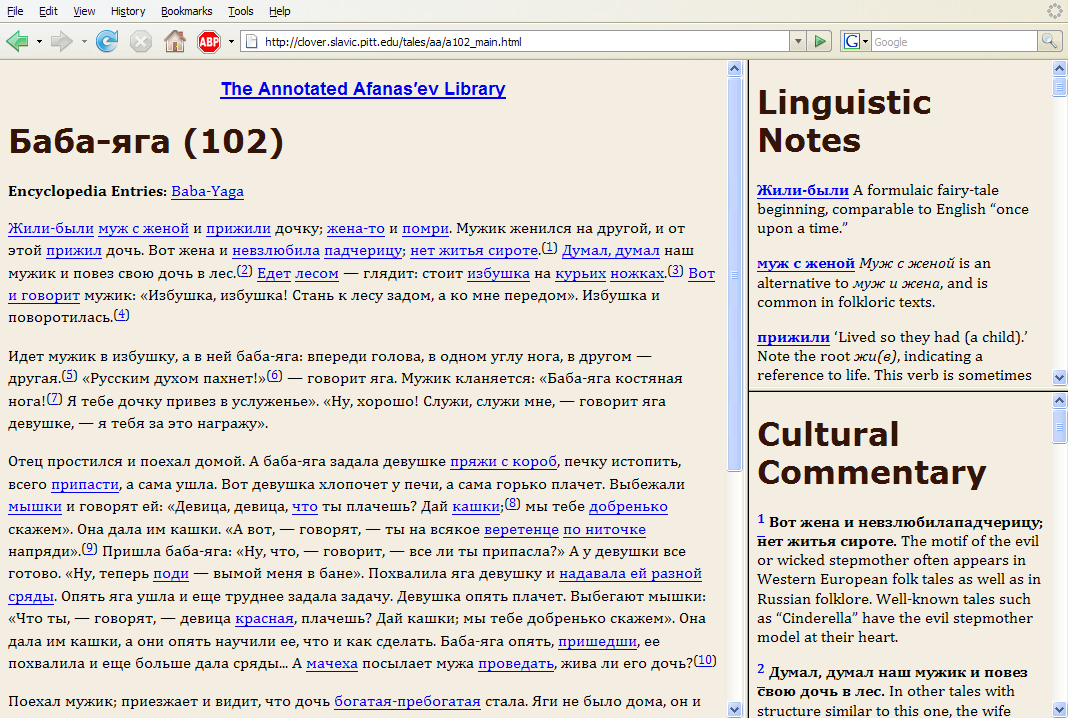
Figure 2. The Annotated Afanas′ev Library
The main window in “AA” is divided into three frames. The left frame contains the main text in which there are two types of clickable links: words and phrases and superscript numbers. The clickable words and phrases are those that might pose linguistic problems for the undergraduate Russian language students who constitute the target audience for this site, and clicking on a word or phrase causes the upper right (Linguistic notes) window to scroll to the appropriate annotation. As with the “Life of St. Paul the Simple” site, the annotations are back-linked, so that clicking on a head word in the Linguistic notes frame causes the main Text frame to scroll, positioning that word at the top of the frame. The superscript numbers identify text that might require cultural or folkloric commentary, and clicking on those links causes the lower right (Cultural commentary) window to scroll. The Cultural commentary entries are also back-linked to the Main text. Finally, there are links at the top of the Main text frame to a small Encyclopedia of Russian folklore and fairy tales, where we record information that might apply to multiple tales (as a way of avoiding repeating the same text in the annotations to each tale).
When we decided to prepare an electronic edition of the “Life of St. Paul the Simple,” we began by considering how the “AA” interface might be adapted for this new project. In “AA” we needed two distinct levels of textual commentary (linguistic and cultural/folkloric), while the “Life of St. Paul the Simple” required just linguistic annotations, a simplification that allowed us to collapse the two right-side frames of “AA” into one in the “Life of St. Paul the Simple.” On the other hand, for the latter project we needed to find ways to enable the user to see the Greek and English text together with the OCS, for which purpose we divided the left side of the window into three frames and created links from the OCS to the Greek and English at the verse level. In an effort to avoid further clutter in the OCS frame, which was already very heavily marked up with links to the Linguistic commentary frame, we put links to the illustrations into the English frame, and we also included the identification of biblical citations and allusions only in the English frame (note the reference to Daniel and link associated with the text “standing on a rock” in the English frame in Figure 3).
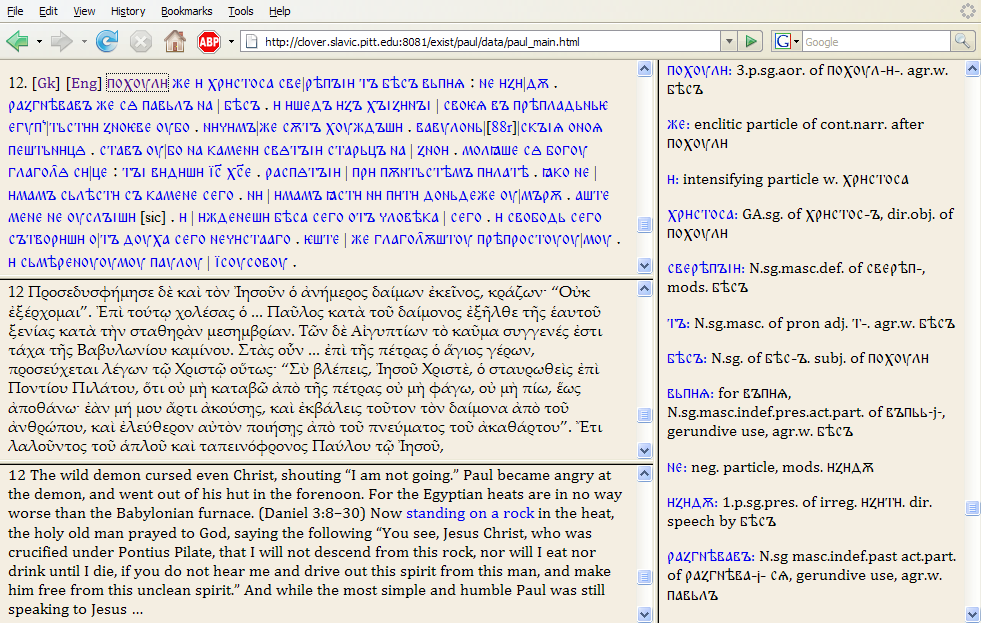
Figure 3. Example of biblical reference and link to illustration in the English frame.
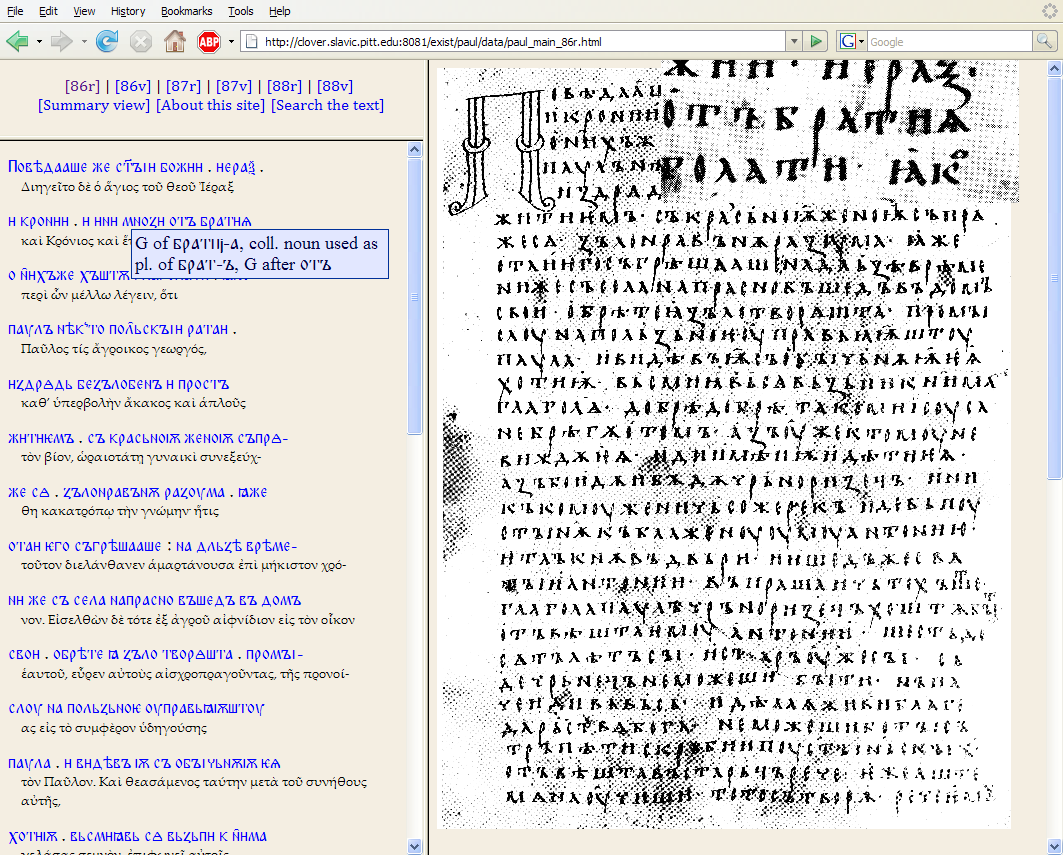
Figure 4. Page view.
The Page view (Figure 4) is a framed interface with three windows, two on the left and one on the right, with the following characteristics:
The predecessor of the Page view is an interface initially developed for the “e-PVL”, an electronic edition of the Rus′ Primary Chronicle, illustrated below:
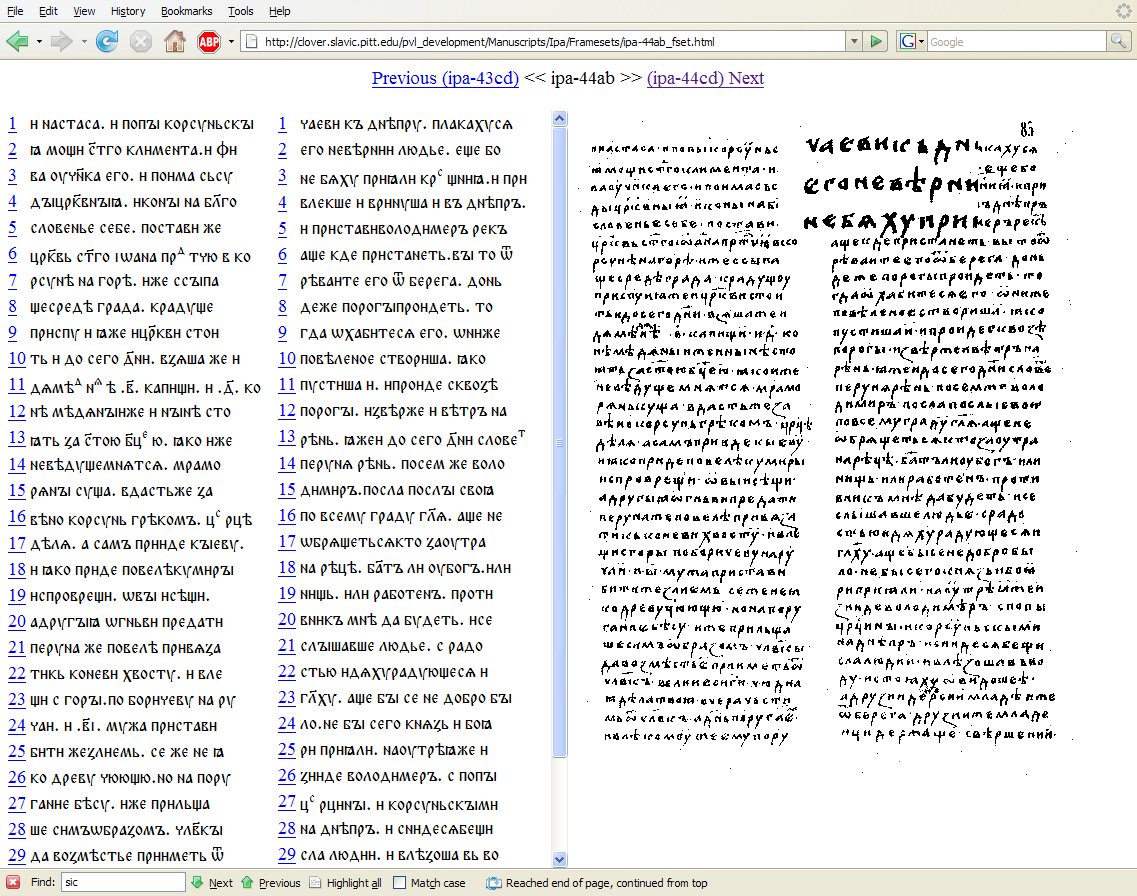
Figure 5. A page of the Hypatian copy of the Rus′ Primary Chronicle.
For both the “e-PVL” and the “Life of St. Paul the Simple” we recognized that some users would prefer to read the text in a character-based transcription (which is more legible), while others would need to have access to the facsimile (which is more faithful). Rendering both side-by-side makes it possible for users to read whichever best meets their needs, while also providing easy comparative access to the other view whenever that might prove necessary or desirable. The magnifying glass Javascript code,
In the case of the “Life of St. Paul the Simple,”
however, we were able to incorporate additional functionality. In particular, it
seemed useful to include an interlinear parallel view of the corresponding Greek
text for each line, so that the Greek would always be accessible to users, and
we rendered it in a smaller type size so that it would not intrude on or compete
with the more important OCS. We incorporated the magnifying glass in order to
meet the needs of users to see both the full page at a glance and closeups of
specific portions of the page. We included links from the Main view to the
individual pages so that users who were reading the text in paragraph form and
needed to check a detail in the transcription or facsimile of a particular page
could move easily to the appropriate page. Finally we wanted to make the
linguistic annotations available from the Page view perspective, but the
transcription and image files already occupied all the available screen space,
so we moved the annotations into pop-up tooltips that would materialize whenever
the user moused over a word in the OCS transcription. Because regular HTML
tooltips (implemented with the @title attribute) do not allow
internal markup, it would not have been possible to combine different fonts in a
single tooltip, a limitation we overcame by employing an enhanced Javascript
tooltip library.
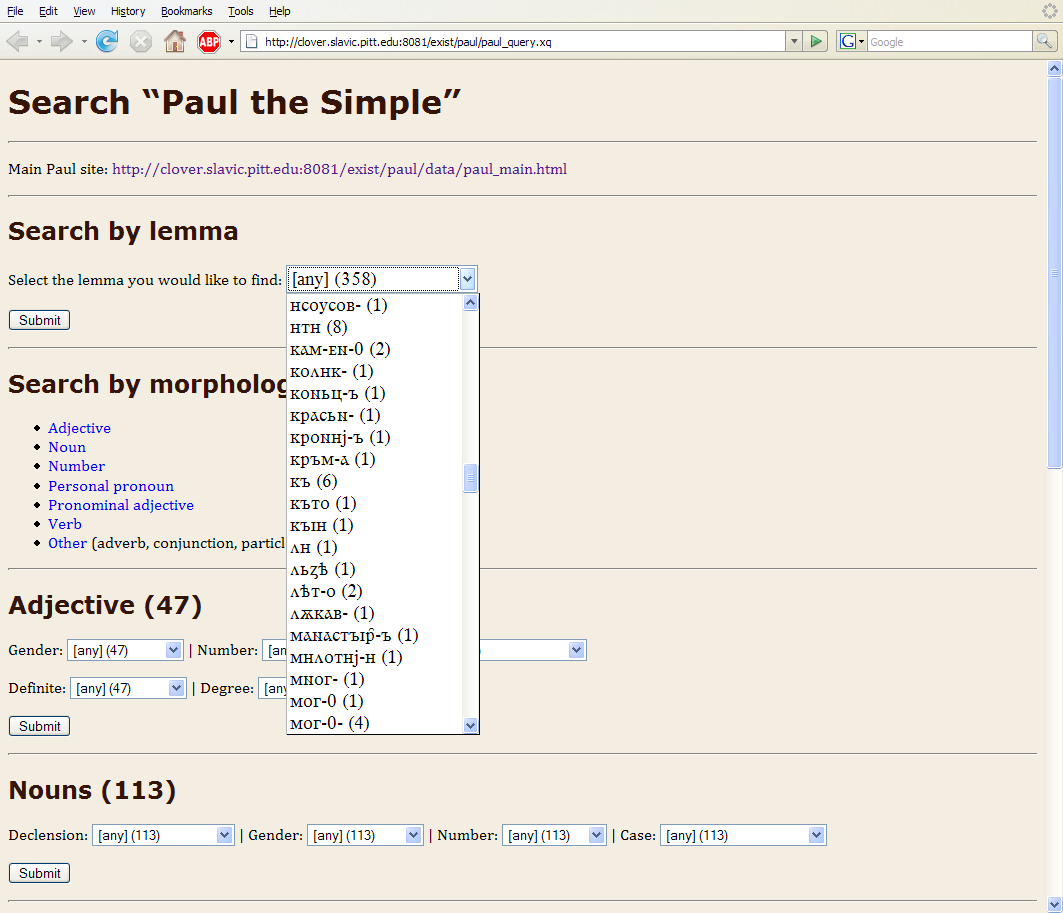
Figure 6. Linguistic search interface view.
The Linguistic search interface (Figure 6) provides a series of HTML search forms, as follows::
Figure 7 shows the output of a search for all neuter nouns in the text:
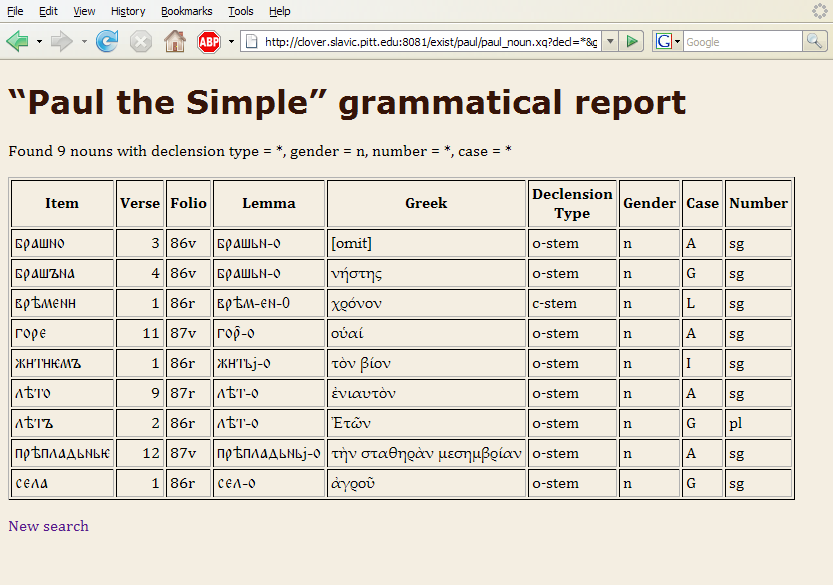
Figure 7. Output of search for neuter nouns.
A linguistic search interface is the feature most often requested by users of the “e-PVL,” and the much smaller scale of the “Life of St. Paul the Simple” allowed it to serve as a manageable test-bed for this type of functionality. The most innovative feature of the query form is that it is constructed on the fly each time the user navigates to the URL, which lets it calculate dynamically the number of items in each category (note the numbers in parentheses in various places in Figure 6). This means that the form adjusts itself automatically to changes in the markup (such as annotating a two-word phrase either as one item or two). While most of the categories are predetermined (e.g., the category of gender always has masculine, neuter, and feminine as possible values, even when the count in one of these categories for a particular part of speech may be zero), the list of lemmata is compiled on the fly, so the form adjusts itself automatically as we modify the identification of lemmata in the corpus.
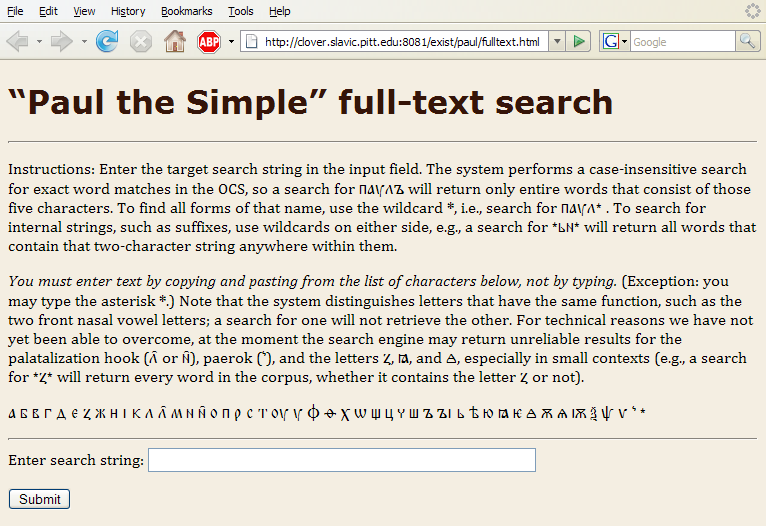
Figure 8. Full text search interface.
The Full text search inteface (Figure 8) allows the user to search for a string of characters anywhere in a word, and return a list of matching items together with lemma, Greek counterpart, and all available grammatical information (see the sample output in Figure 9).
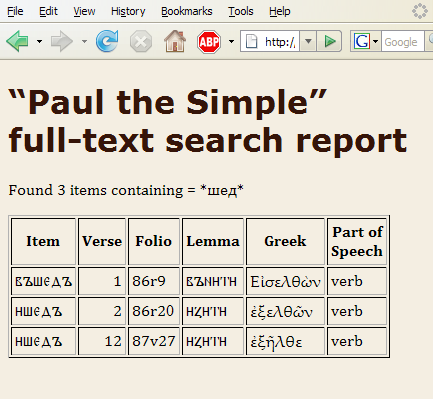
Figure 9. Output of full text search for *шед*.
The full text search engine looks for entire words that match the search string exactly, which makes it easy to find entire words. For example, that a search for въ would return only full words that consist of the two letters (i.e., the prepositionвъ), but not any occurrence of those two letters when they do not consitute a word. The system also supports the asterisk (*) wildcard, which stands for a sequence of zero or more non-space and non-punctuation characters, so that a search for *въ* would retrieve all words that contain a sequence of those two characters anywhere within them (whether as the entire word or as part of the word). This feature is particularly useful when searching for morphemes (e.g., the adjectival suffix ьн, although a search for *ьн* will also retrieve the noun дьнь and other false positives) or lexemes irrespective of ending (e.g., паул* will retrieve all case forms of the name, although this type of retrieval is also possible through a lemma search).
Full text searching is easily available in the Main view because web browsers provide a string search “find” feature, but the Full text search interface returns a convenient list of matches along with all relevant grammatical information, arranged in tabular form. Furthermore, the “find” feature of web browsers does not support wildcard searches, and although it searches for substrings automatically (and therefore does not require leading or trailing wildcards), it has no support for the equivalent of internal wildcards (e.g., a search for all verbs that begin with the prefix съ– and end with the reflexive particle сꙙ.
The “Life of St. Paul the Simple” project is implemented in eXtensible Markup Language (XML), and uses related structured text and Internet technologies. XML (http://www.w3.org/XML/) is a Worldwide Web Consortium (W3C) standard for encoding structured text. It is similar to Hypertext Markup Language (HTML, http://www.w3.org/html/), the language used to deliver web pages, except that it allows the user to identify (“tag”) text according to its meaning or function, and not merely its appearance. Thus, each word in the “Life of St. Paul the Simple” carries with it annotations about its lemma, its linguistic properties, its Greek counterpart, etc.
One of the most valuable aspects of XML for a project of this sort is that because the document is annotated according to the meaning and function of its parts, rather than according to their appearance, it is possible to generate multiple views from the same source document. For example, the OCS in the Main view is combined in a single web page, it is broken into verses that are laid out like paragraphs, it incorporates vertical lines to mark the ends of lines in the source manuscript, it identifies page numbers in the manuscript, and it includes links to the corresponding Greek and English versions. The OCS in the Page view, on the other hand, is divided into lines according to its layout in the manuscript, there are no vertical bars to mark line ends, and there are no page references (except that each manuscript page is a separate web page). In the Main view, mousing over a word in the OCS does nothing, but clicking on it scrolls the Linguistic commentary frame. In the Page view, clicking on a word in the OCS does nothing, but mousing over it causes a tooltip to materialize and hover. These two very different views of the data are generated programmatically from a single XML source file, which means that it is impossible for the data to get out of sync (e.g., the linguistic commentary in the Linguistic commentary frame of the main view will always be exactly the same as the linguistic commentary in the tooltips), and any modification to the project needs to be made only once and in only one place, whereupon it will automatically migrate to all relevant views. Furthermore, because the linguistic annotations and other links are embedded alongside the words to which they apply in the XML source file, all links across frames are maintained automatically. Adding or removing an annotation does not require renumbering, and it is impossible for any generated link to point to the wrong target (or to a non-existent one).
The source XML is converted to HTML (in multiple forms) for delivery on the Internet with the help of eXtensible Stylesheet Language Transformations (XSLT, http://www.w3.org/TR/xslt), which is a specialized programming language that is designed to transform XML into other forms. Since HTML can be conceptualized as an implementation of XML, XSLT is very well suited for XML-to-HTML transformations. XSLT works together with XML Path Language (XPath, http://www.w3.org/TR/xpath), which provides a mechanism for XSLT to identify and transforms specific portions of an XML document according to instructions that the user specifies using XSLT.
The Linguistic and Full text search interfaces are based on XML Query Language (XQuery, http://www.w3.org/XML/Query/), which also uses XPath as its addressing mechanism, and which enables users to operate with XML similarly to the way one might interact with a relational database. XQuery is thus ideally suited for searching XML documents quickly and generating structured reports (in HTML in the case of the “Life of St. Paul the Simple” project).
The decoration (font selection, colors, layout, etc.) of the output HTML pages is governed by Cascading Style Sheets (CSS, http://www.w3.org/Style/CSS/), a W3C standard designed to provide control over the rendering of documents on the Worldwide Web. On-the-fly modifications of rendering styles (e.g., highlighting of words during searching, the Font switcher described below) are controlled by Dynamic HTML (DHTML, see http://developer.mozilla.org/en/docs/DHTML), which weds CSS to JavaScript (see http://developer.mozilla.org/en/docs/JavaScript) to enable users to modify the appearance of web pages on their browsers without having to reload any information from the original server.
Although the “Life of St. Paul the Simple” is a fairly small project in terms of the amount of source data, the need to develop multiple views of the same data and to keep them in sync would have made it impossible to develop and maintain traditional web pages by authoring them manually without serious risk of introducing errors and inconsistencies in coding. The technologies described above insure the consistency and structural integrity of the data in ways that would not otherwise be available.
Unicode (http://www.unicode.org) is a multilingual character set standard that underlies all modern computer operating systems (including Microsoft Windows, Mac OSX, and Linux) and most modern application software. It is updated periodically to expand support for writing systems; Version 1 (1991) contained full support for modern Slavic languages written in Cyrillic as well as limited support for early Cyrillic, Version 4.1 (published 2005-03-31) introduced support for Glagolitic, and Version 5.1 (published 2008-04-04) greatly expanded the support for early Cyrillic. In particlar, 5.1 is the first version of Unicode that distinguishes modern я from early ꙗ, modern з from early ꙁ, the closed front nasal ꙙ from the open ѧ, and the early sequence оу from the vertical ligature ꙋ.4
Our edition of the “Life of St. Paul the Simple” uses the new Unicode 5.1 characters. This means that although the pages can be rendered without any special fonts, the new characters will be displayed correctly only if the user has Unicode 5.1 compatible fonts installed. The project directly supports six such fonts:5
Our system uses Cascading Style Sheets (CSS) to render OCS text and Greek text in particular fonts, as follows:
Users can override the default font selection by using the Font switcher (see Figure 10):
Figure 10. Font switcher.
The Font switcher (Figure 10) incorporates a drop-down list of the six free Unicode 5.1 compatible fonts listed above. Alternatively, users who have their own Unicode 5.1 fonts not included in the drop-down list may specify the name of the font (its font name, not its file name) and hit the Submit button. Once the user has made a selection (whether in the drop-down list or in the text input box), the Font switcher changes all OCS text to the selected font. It also sets a cookie on the user’s system, which enables it to remember the user’s preference the next time the site is accessed. When the user selects a font, the Font switcher attempts to discern whether that font is installed on the user’s system. If so, it changes all OCS text to that font. If not, it alerts the user that the font in question is not available.6
The “Life of St. Paul the Simple” is the first medieval Slavic text published on the Internet in Unicode 5.1. While developers could work around certain lacunae in the early Cyrillic support in Unicode 5.0 (e.g., using the codes for modern з or я to represent early ꙁ and ꙗ, respectively), the use of ꙙ and ѧ to represent the non-jotated and jotated front nasal vowel, respectively, posed an insurmountable problem, since Unicode 5.0 lacked any adequate way of representing the ꙙ characater. Thus, Unicode 5.1 makes it possible for the first time to represent texts from the Codex Suprasliensis in a standards-conformant way. This means that users will be able to use any Unicode 5.1 conformant font to render the OCS in this edition, and the text can be migrated to other platforms and applications without concern about non-standard encoding.
The Font switcher was developed originally for the “e-PVL”, and then modified to support the Unicode 5.1 encoding used in the “Life of St. Paul the Simple.” Because users often have preferences concerning the appearance of their documents, the Font switcher enables the developer and the user to cooperate to render the document accurately, but in a way that addresses the latter’s aesthetic preferences.
Put some conclusions here.
The Codex Suprasliensis, a Cyrillic parchment manuscript datable to the eleventh century, is the largest extant Old Church Slavonic codex (285 folios). It contains most of a menaeum (devotional and edificatory readings arranged by the church calendar) for the month of March and selected other texts of a religious character. The manuscript was discovered in the early nineteenth century in a monastery library in Supraśl, Poland. Later in the century it was divided into three parts; currently there are 151 folios in the Polish National Library in Warsaw (Zamoyski Library Collection BOZ 201), 118 in the Library of Ljubljana University (Cod. Kop. 2), and 16 in the Russian National Library in St. Petersburg (Bychkov Collection Q. perg.I.72).
The authors are grateful to Sebastian Kempgen, Wendell Piez, and Mark Weixel for comments and suggestions.
1 Each word was identified by part of speech and all applicable grammatical categories. For example, nouns were identified according to gender, declension type, case, and number. Verbs were identified according to the categories relevant for the tense or mood (for example, case was required for participles but not for present tense forms, person was required for present tense forms but not for participles, etc.).
2 For morphological reasons we group къто, чьто, and their negative and indefinite compounds together under the rubric of Personal pronoun.
3 For morphological reasons we group possessive, demonstrative, quantitative, and relative pronouns together under the rubric of Pronominal adjectives.
4 The Unicode 5.1 characters in the preceding sentence will be garbled if you do not have a Unicode 5.1 compatible font installed on your system. Should that happen, please download and install one of the fonts listed in the following paragraph and try again.
5 Because these are regular TrueType fonts, their utility is not restricted to viewing web sites, and they can used in any application that allows users to select fonts (e.g. word processors, etc.).
6 This “font sniffing” relies on the browser’s standardized behavior, which means that it may give erroneous information in some browsers on some operating systems if they deviate from the applicable standards.